達觀數據:用好學習排序 (LTR) ,資訊信息流推薦效果翻倍
近線:準實時捕捉用戶實時行為并做出反饋,即近線模塊的輸出需要考慮用戶的實時行為反饋。該模塊一般處理延遲為秒級。
離線:基于分布式平臺離線挖掘,輸出包括item-base協同過濾結果、基于標簽的召回結果、各維度熱門結果、用戶畫像等等。該模塊的處理延遲一般為小時級或者天級。
一個通用的資訊流推薦架構如下:
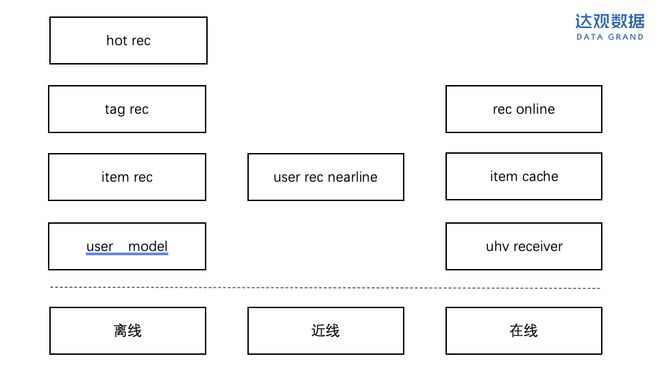
圖1:--三層架構
hot rec模塊負責生成各個維度的熱門結果,如分類別熱門、分地域熱門;生成各個標簽的召回結果,如 英超 -> (,,….);item rec生成每個資訊item的相關結果;user rec 根據用戶實時行為和離線畫像負責生成用戶的推薦結果;響應推薦請求;item 返回資訊的信息;負責接收用戶對item的行為反饋。關于架構可參考更過之前達觀數據發布的推薦技術文章。
為什么需要學習排序
學習排序(LTR: to rank)是信息檢索領域的經典問題,也是互聯網場景中這個核心算法問題。推薦整個流程可以分為召回、排序、重排序這三個階段,通俗來說,召回就是找到用戶可能喜歡的幾百條資訊,排序就是對這幾百條資訊利用機器學習的方法預估用戶對每條資訊的偏好程度,一般以點擊率衡量,所以學習排序在很多情況下等同于點擊率預估,都是將用戶最可能點擊的資訊優先推給用戶;重排序更多考慮業務邏輯,如在推薦結果的多樣性、時效性、新穎性等方面進行控制。
在沒有學習排序之前,也可以單純使用協同過濾算法來進行推薦。列如使用用戶最近點擊的資訊信息召回這些item的相關結果和偏好類別熱門結果組合后進行返回。但是這對于資訊類推薦需要考慮一下問題:資訊類信息流屬于用戶消費型場景,item時效性要求高,item base cf容易召回較舊的內容,而且容易導致推薦結果收斂。因此可以將item的相關結果保證時效性的基礎上,融合類別、標簽熱門結果,對各個策略的召回結果按照線上總體反饋進行排序,就可以作為用戶的推薦結果。但是這一融合過程比較復雜,一種簡單的方式就是看哪種召回策略總體收益越高就擴大這個策略的曝光占比,對于個體而言卻顯得不是特別個性化,而且在規則調參上也比較困難。
LTR架構
我們迅速在資訊信息流推薦場景上實踐ltr算法。Ltr一般分為 wise、、list wise,一般工程上使用較多,簡單,成本低,收益也可靠。簡單來說,Ltr即預測user對一個未消費item的預估點擊率,即:
即這個預估的點擊率是和user、item、相關的。我們使用邏輯回歸( ,lr)模型來搭建我們第一版的學習排序架構,lr模型簡單可解釋,缺點在于需要對業務特征有較深理解,特征工程比較費力,但從應用角度出發,無論是lr、ffm亦或是較新的wide& deep等模型,特征挖掘都是極其重要的一環。因此在首先基于lr模型的基礎上,核心工作就是基于業務理解并發掘特征。以下是排序模型的整體推薦架構。
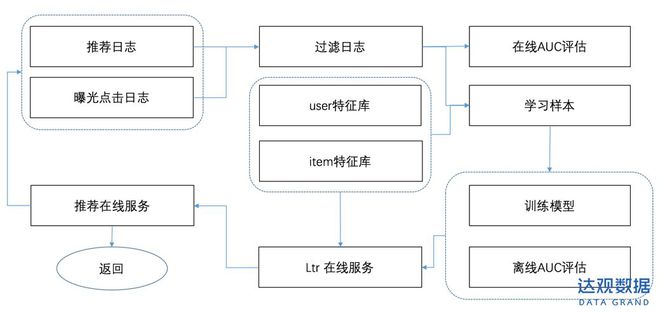
圖2:ltr整體架構
日志過濾
推薦日志詳細打印了每次推薦請求的參數信息和返回信息,如屏數、請求個數、設備信息、位置信息、返回的推薦結果。推薦日志需要盡可能的考慮后期可能使用到的特征,并做好充分的記錄。將推薦日志與曝光日志進行第一次join,過濾掉未曝光即用戶沒有看到的推薦item,這部分樣本沒有參考意義,可以省略;第一個join后的結果與點擊日志join,即可以得到每條樣本的(0/1:未點擊/點擊)。兩次join需要根據請求時間、、三者進行 join,確保數據準確。日志過濾后生成的每條樣本信息如下:
[請求時間、曝光時間、點擊時間(如果有)、、最近的點擊item列表、最近曝光的item列表、、召回策略、屏數、曝光順序位置、地理位置、設備信息] –> 點擊。
特征工程
經過1)的樣本缺少足夠的特征,我們需要補充user和item端的特征。該部分特征需要離線挖掘并提前入庫。總結后的可使用特征種類大致如下:
特征種類
User特征:手機型號、地域、圖文曝光/點擊總數、視頻曝光/點擊總數、圖文點擊率、視頻點擊率,最近1、2、3天圖文視頻點擊數、最近點擊時間、最近一次點擊是圖文還是視頻、一二級類別點擊率、標簽偏好,類別偏好、最近16次點擊的素材分布、最近16次點擊item的平均標題向量、曝光時間、點擊時間等;
item特征:、類別、總體點擊率、最近一周點擊率、圖片個數、來源、類型(圖文還是視頻)、發布時間、標題向量、召回策略、點擊反饋ctr等;
特征:屏數、曝光順序位置、請求時間段等;
交叉特征:用戶對item類別的一二級類別點擊率、用戶對item標簽的偏好、用戶對item素材類型的曝光、點擊次數和點擊率、最近16個點擊item與預測item標題向量的余弦相似度、相似度最大值等。
交叉特征對于特別重要,核心在于邏輯回歸函數中,如果與預測item無關的特征不會對item的排序產生影響,只有item特征或者與item交叉的特征才會對排序有實質影響,因為其他特征對任何待預測item的打分貢獻是一樣的。
我們沒有使用 word模型來表示標題,因為這非常稀疏,而是采用標題中關鍵詞的向量組合生成標題表示,使用詞向量來表示標題極大減少了特征規模,實現上比較方便。標題向量同時需要歸一化成單位向量,單位向量的余弦相似度即兩個向量的內積,這個優化顯著提高了ltr在線模塊的性能。
我們將所有特征按類型劃分為離散型、連續型、向量型三種類型。如item類別就是一個離散型特征、item ctr就是一個連續性特征、標題向量就是一個向量型特征。對于每種特征,其處理方式都會不太一樣,對于離散型一般直接根據離散值做 name,對于連續值我們部分參考 wide & deep論文中的等頻歸一化方法,簡單來說加入ctr特征需要等屏成10個特征,即將ctr值按照分布取其10等分點,這10等分點就定義了10個區間,每個區間的樣本數都占10%。需要注意的是,ltr在線部分需要寫死這10個區間來提高特征離散化的效率。
由于離線和在線都會需要User和item端特征,我們在hive數倉和ssdb集群總中都存儲一份,離線負責join hive表,在線負責讀取ssdb。
模型訓練與評估
經過特征工程后,訓練數據按照格式進行打印。使用一天的訓練數據的情況下,整個特征空間規模約為30萬維左右。模型訓練采用的 模型進行訓練,方便dump和load模型,我們采用了算法來進行訓練,是一種擬牛頓法,不同于隨機梯度下降,總是朝著最優化梯度方向進行迭代。
簡單起見,我們使用N-2天前的日志做訓練,N-1天前的日志做評估,需保證兩部分日志的用戶群體是一致的,我們再做ab測試的過程中,不能訓練數據用的是1號桶,評估數據用的是2號桶。
實際過程中,我們采用1500萬條樣本做訓練,300萬條樣本做評估,訓練完成后離線auc為0.79-0.8區間內,在線auc為0.75-0.76區間內,存在一定差距。關于auc可以自行參考技術文章,簡單來說auc就是衡量模型將正樣本排在負樣本前面的概率,即排序能力。
在線服務于評估
我們的最終目的是要在線上流程產生收益,我們采用rpc搭建了一個ltr在線服務,負責接收的ltr請求。推薦在召回各個策略的結果后,會將、預測的列表、等信息傳給ltr ,ltr 打分后返回。我們對ltr 做了充足的優化,包括標題向量的單位化、ssdb性能優化、特征離散化的優化,顯著提高了性能,對200-300個item打分的平均響應時間控制在以內。
模型不僅需要離線評估,還需要在線評估,在線評估即評估在線樣本的auc, log中記錄了ltr ,因此可以方便的計算在線auc。計算在線auc的目的是為了驗證離線效果提升和在線效果提升的同步性。
業務效果的提升
我們在測試組上線ltr邏輯后,在點擊率指標上相比原算法取得了明顯的提升。如下圖所示:
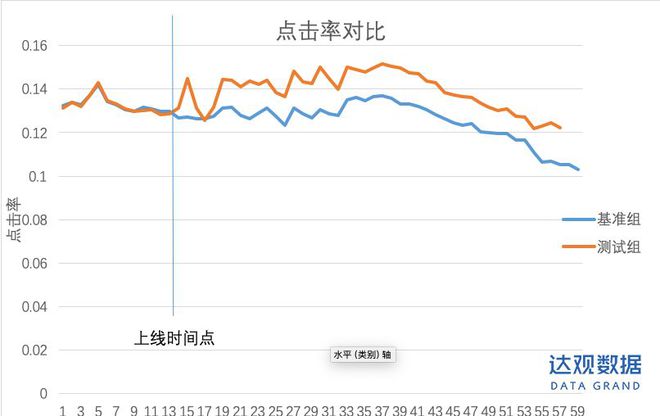
可以明顯看出上線后,基于點擊率目標的ltr對于天級點擊率的提升是非常明顯的。
問題探討
單機訓練大規模樣本
由于選取的樣本數較大,1000-2000萬的規模,簡單增大樣本數可以顯著提高auc,在我們的場景上在往上增加auc就似乎增加不明顯了。這么大的訓練樣本單機訓練的話顯然只能用稀疏矩陣的方式來存儲樣本。的就是非常好的選擇,由于的轉載時數組下表采用int,故最大空間只能到20億,顯然2000萬樣本* 每個樣本的平均特征數遠遠大于20億,因此我們探討了如何加載大規模數據的方法,最終我們參考工具包中加載格式數據的代碼,當然加載方式也存在問題,經過修改調試后,成功的完成了訓練數據的加載,具體問題和解決方式可以參考這篇文章。
樣本和特征的時間正交
樣本和特征數據的時間正交即兩者在時間上不應該有交叉。舉個例子,前期我們在join用戶端特征時,用的是1號的訓練樣本數據,用戶離線特征用的也是1號的數據,這樣兩者就會存在交叉,即user點擊了一篇英超新聞,同時user 畫像中也偏好英超標簽(由1號的點擊生成),這樣就會導致auc偏高,當然這種偏高就是虛假偏高,模型的泛化能力是很差的。在實際過程中,遇到過幾次auc突然偏高的情況,發現大部分都是由于沒有保證數據正交性導致的。
在整個流程中,數據的時間正交總是被不斷強調。無論是user、item特征還是樣本數據,比如訓練樣本中一個特定user的樣本按照時間排序是(s1,s2,s3,s4,s5,s6,s7,s8,s9,s10),使用s1-s8訓練,s9,s10評估是合理的,而使用s3-s10訓練,s1,s2則顯然是不合理的。
預估點擊率和實際點擊率的一致性
點擊率預估基本要求就是預估的點擊率要精準,如果只考慮位置的,可以不用過分關心預估的絕對值,但實際情況下還是需要盡量保證預估分數的合理性,往往預估精準的ctr具有很大的參考價值。
前期我們預估的點擊率一直偏高,平均打分甚至達到了0.5,經過排查在于訓練模型的參數設置不合理,錯誤的將的參數設置成,導致損失函數中正樣本預測錯誤的代價增大,導致模型偏向正樣本,從而導致預估的點擊率極度偏高,修復成默認值預估點擊率下降明顯,接近實際值。具體參考:。
同時為了保證訓練數據和在線服務完全一致性,我們調整了推薦的整體架構,更多的直接在推薦模塊負責召回和排序,這樣又可以進一步保證預估點擊率和實際點擊率的一致。
重要特征和 case排查
lr模型可以方便每個樣本的各個特征和權重,權重高的特征顯然更加重要。如果你覺得重要的特征權重過低了或者不重要的特征權重過高了,也許就要思考為什么了。以下是一個樣本的信息。
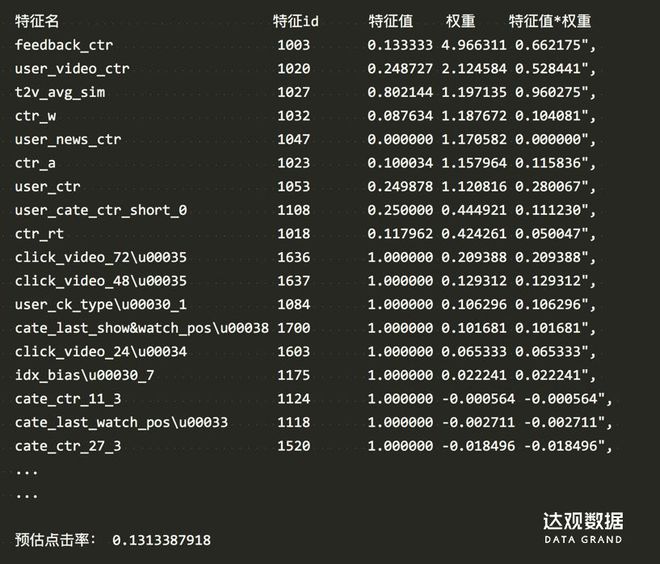
例如我們發現ctr特征權重特別高,假設一個新item曝光了一次點擊了一次,點擊率是1.0,乘上ctr的權重上這個item極易被排到最前面,因此我們考慮ctr的置信度,考慮對ctr類特征做了平滑。
值根據實際情況設定。
總結
本文詳細介紹了達觀數據的推薦引擎架構和在資訊信息流推薦場景中利用ltr排序顯著提高業務指標的實踐和經驗。由于篇幅有限,關于非線性的ffm、wide & deep沒有做詳細介紹,而這也是算法團隊一直繼續投入研究的重點。
BOUT
關于作者
文輝:達觀數據聯合創始人,主要負責達觀數據推薦系統、爬蟲系統等主要系統的研究和開發。同濟大學計算機應用技術專業碩士,曾就職于盛大文學數據中心部門,負責爬蟲系統、推薦系統、數據挖掘和分析等大數據系統的研發工作,在爬蟲系統、/Hive、數據挖掘等方面具備充足的研發和實踐經驗。
聲明:本站所有文章資源內容,如無特殊說明或標注,均為采集網絡資源。如若本站內容侵犯了原著者的合法權益,可聯系本站刪除。
